It’s August of 2022.
I’ve understood as much of the tech stack powering blockchains that my brain can hold without exploding. I’ve learnt the basics of smart contracts and security from CryptoZombies and Ethernaut. I’ve dabbled in DeFi as a user and tried to understand how each of the protocols were designed. It’s time to build something of my own.
Luckily, my friends and I were playing around with the idea of a platform where traders could launch actively managed on-chain funds and people could put money in them. It sounded just the right amount of crazy to me that I could vaguely understand which direction to code in, without anticipating all the problems that would come up. This article will discuss the surprising, unanticipated technical learnings from building Barren Wuffet - with the lens of a fresh-faced web3 dev.
The scope of this article is limited to the technical aspects only. If you want to learn more about the intended purpose of the project, or the nitty gritty details of the smart contract, please check out the docs at https://barren-wuffet.gitbook.io/barren-wuffet/. If you want to know why it ultimately failed, please read the business post-mortem.
Everything I write here is predicated on my own experience circa August 2022. If you have feedback regarding what I could have done better, or if things have changed, please reach out to me on Twitter or comment below so I can update this article!
I’ve split this article into 4 sections: Backend, Infra/Tooling, Frontend and Community. While Web3 systems don’t transfer directly to the Web2 model, it’s an okay way to think about the different aspects of the project.
Let’s dive in!

Backend
EVM ヽ(`⌒´ メ)ノ
By far my biggest frustration was EIP-170 shipped with the Spurious Dragon Hard Fork to counteract DoS vulnerabilities found during the Shanghai Attacks. I’ve hit this limit at least 3 times as my system evolved to be more complex. Everytime I dreaded the thought of having to refactor to fit within the 24KB limit. This article by soliditydeveloper outlines the different things you can do to be within the limit.
TLDR:
- separate your contracts well (I was doing this),
- use libraries (I wasn’t really doing this, but this created a nice side effect of making the whole thing more readable),
- use proxies if the contract is deploying child contracts (see below)
- write only what you must in contracts (see below)
- shorten error messages (ended up marking reverts with
"OW1"and having comments at the top of the file to explain what they mean) - change optimizer value to 1 (don’t have to think too much about gas optimization if I’m on an L2, right?!)
Proxies Galore
There are mainly 2 reasons I had to use proxies in the system:
- The main contract was deploying child contracts, and I couldn’t pack the child contract’s bytecode into the main contract’s without hitting limits.1
- We wanted to be able to upgrade contracts without having to redeploy the whole system. (at least until we were out of Beta)
Proxies are confusing since there are different kinds that evolved over the years, with different use cases and tradeoffs and future consequences. OpenZeppelin has a well written guide but I’ll be lying if I say I remember much. The annoying thing is that you have to be aware of the proxy pattern you’re using, think through the workflows and then change your contracts to fit the pattern. Proxies separate the contract logic and data store; And this can have serious security implications if not handled carefully. It takes you away from the business logic you’re trying to solve. It may be fun to learn, but definitely not fun to test.
Take a look for yourself. We were using Upgradable Beacon Proxies2, if I remember correctly.
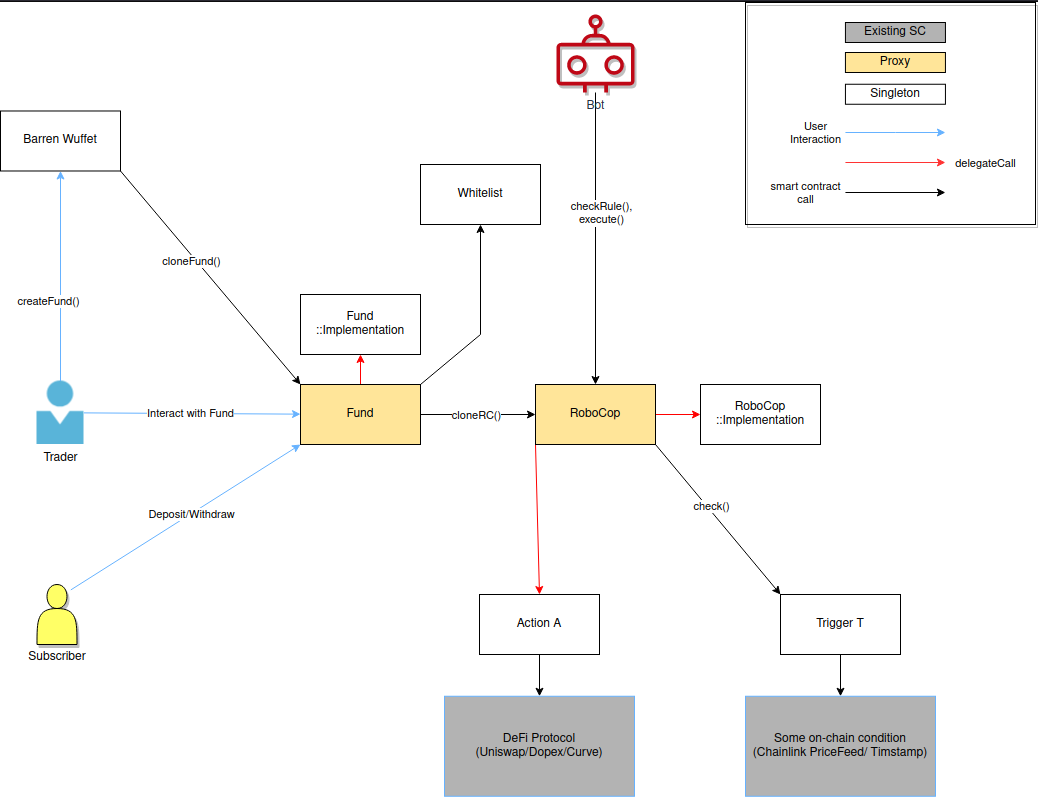
What Should The Contract Do?
If gas was free (i.e. the EVM was infinitely scalable), this wouldn’t be something to consider. Just throw in convenience functions, store everything, make the frontend dumb as hell. But gas isn’t free, so you have to think about exactly what smart contracts are for. Smart Contracts are for replacing trusted third parties. They are not “just a database”. They are for enforcing rules in a system, for which they need to store a minimum set of data. This minimum set of data will also be used by the frontend to display information to the user. However, you also have to consider the problem of third party dependency here.
Let’s take an example to illustrate the problem better. In Barren Wuffet, fund managers would be able to create IFTTT rules for the future, which would be automatically executed in the future. Now, EVM doesn’t have an automatic TX execution hook like that3, so someone4 has to send a TX to trigger the execution. The smart contract has to make sure whatever is being triggered matches the IFTTT rule the fund manager specified (otherwise a whitelisted bot run by the fund manager will have to do it, which defeats the point of the setup 5). To do this, the smart contract has to store some info verify the rule that’s being executed. There are 2 ways of doing this:
- Smart Contract stores the entire IFTTT rule with all its triggers, actions and their parameters and gives back an identifier for this rule. Later, someone can send a TX saying
execute(id). Smart Contract would lookup in a mappingid => IFTTTRule, check that on-chain trigger conditions are met and execute the actions. Frontend would only have to be aware of the id. This incurs extra gas cost at rule creation time because we are storing the entire rule in the contract. - Smart Contract stores a hash - a deterministic unique identifier - of the IFTTT rule. When some bot thinks it’s time to execute the rule, it sends a TX saying
execute(IFTTTRUle)and the smart contract just checks that the hash of the IFTTT rule matches the hash it has stored. Frontend would have to be aware of the entire IFTTT rule (it would read this from the events emitted by the contract). This incurs extra gas cost at execution time because we are sending the entire rule as calldata to the contract. This is more akin to the “UTXO model” of Bitcoin and Cardano.
In both these cases, you need to think about “data availability”. Do you expect frontends to keep track of the entire history of the contract and lookup/reconstruct the data? Do you use something like The Graph that the frontend queries? What happens if The Graph goes down? (see more below). Does the gas cost economics make sense for the use case?
No clear answers!

“Admin” Functions - Where’s The Balance?
If you come from a web2 backend world, you’re used to being a “superuser” who can do anything - mostly for fixing bugs. This is not the case in Ethereum.
You can get to an abusive level of power with onlyOwner modifiers, but then would users use the product?
You could decentralize the onlyOwner invocations with a DAO model, but would that have enough velocity to catch and fix bugs in the future?
No easy answers here either. What we ended up doing is limiting the onlyOwner functions to the bare minimum - pausing during an attack, upgrading the contract logic, and then designing an emergency “escape hatch” for the community to use in case they feel this power is being abused. We wanted to retain the ability to move fast (i.e. have a small multisig of founding team), with plans to decentralize some things in the future (DAO), deprecate the upgrade-ability (why would you need this if it’s been stable for a while on mainnet?) and then finally remove the onlyOwner functions altogether.
Open a dialogue with your community and see what they are comfortable with.
Test, Test and Test Some More \(º □ º l|l)/
I hate writing tests.
There was a running joke on the team - if you want Psyf to be productive, ask him to write tests and he’ll get everything else in the org done first just to avoid writing tests.
Jokes aside, props to Madneutrino for setting up the first set of tests and getting me to write more (even though a redesign made us remove EVERY TEST I HAD PAINSTAKINGLY WRITTEN…UGHHHH). Tests meant I was able to refactor the codebase and make changes (add/remove) with confidence that I did not break something - especially when it came to large scale refactors involving proxies and contract size.
Tests with very high coverage are particularly important with smart contracts because they are immutable (barring doors you create for yourself using proxies). Bugs can be expensive, and the entire contract is open for anyone to exploit.
The setup / teardown tools provided by hardhat make it easy to instantiate and test the contracts easily. It even gives you information about where in the smart contract the errors happened. You will have to use (convenient af) console.log() to troubleshoot, though.
Debuggability
It’s useful to write good error messages and define every error scenario in a smart contract. Tests that verify the specific error messages in error scenarios are useful here. Once it goes to production, there is no stack trace, since you dont control the backend. You only get the text of the error message you throw.
This can be quite important even if you are contract is functioning fine, you still need to figure out what’s going on when your front end inevitably sends some buggy data to the testnet, and you want to know why on earth the tx reverted!
Another way is to use tools like Tenderly to simulate the reverted transaction step by step.
Decimals…WHY?
The amount of time Madneutrino and I wasted on figuring out how to handle decimals makes me want to cry.
Different popular ERC20s use different decimals.
Chainlink returns different decimals for each price feed.
You have to account for both decimals when doing math like combining ETH/USD and UNI/USD to ETH/UNI.
Different smart contracts expect different decimals when you send them limits for slippage.
Do you lose resolution if you go through this workflow?
Do your order of operations potentially make something go to zero in error?
Are there tokens you can’t handle?
Can you handle events like the UST crash?
It’s a confusing mess. I wish we had just used 18 decimals everywhere.
But then again, the front end user doesn’t want to see 18 decimals of everything. In fact, they mostly want to see values in USD (or maybe ETH). So your significant figures translations have to be rock solid.
We wrote a lot of utils to handle this (feel free to use them!). You can also find similar ones in other defi contracts that handle swaps.
True story, this was the most used gif on our discord for a while.

Can we just all agree to use WETH, please?
The amount of code I had to write for different pathways of ERC20 and ETH for each integration (both input and output combinations) just makes me want to die. I discovered Uniswap v3’s way of writing contracts for ERC20 and using WETH wrapper for ETH way too late :sad-face:
Infra and Tooling
Chainlink, where’s the Feed Registry on Arbitrum Bro?
Don’t get me wrong - Chainlink is awesome and has powered a lot of the DeFi infrastructure. Their integration guides are nice and easy.
BUT, the contract has to know which contract to call to get ETH/USD, and which to call to get UNI/USD and so on…So you have to spend all that gas saving this into your contracts. Then you have to have a workflow for updating these addresses when they change. Chainlink has rolled out a Feed Registry so the contract can query at runtime, but I have zero idea why this is only available on Ethereum Mainnet. So now I have to write this extra contract to act as the chainlink registry when I deploy on other L2s (we were going to do this on Arbitrum, and then mainnet/Optimism/otherL2s later).
We should focus a bit more on DevEx as a space.
Gelato Is Delicious
I initially nerd-sniped myself into the project by thinking about “good MEV” and how to align incentive mechanisms so that an IFTTT ecosystem could have strong guarantees. Ultimately, I caved in and just assumed we were going to use Gelato to start off. Their docs were awesome and the devs in the discord were helpful. I was able to get a working prototype up and running in a few hours!
There are 2 things to nitpick though:
- When I was integrating, they had rolled out some new upgrades to their contracts and the docs hadn’t been updated to reflect that. So I had to go and read the smart contracts and figure things out myself. They’ve now updated them, but I bring this up because I’ve seen this happen in multiple protocols.
- Their bot is closed-source and the network hasn’t decentralized yet. So I had to write extra code to pretend to be the bot in my integration tests. So even though I did assume we’re going to use Gelato, I had to design the code such that it would be easy to swap out the Gelato integration for something else (e.g. a bot the DAO maintained, or anyone else could participate in for altruism/MEV).
Forking Is Awesome
I was dreading setting up hardhat for forking Arbitrum Mainnet, but it was actually pretty easy6. This is perhaps my favourite feature of developing smart contracts. You just grab an API key from Alchemy and then you can fork mainnet and test your code against it. You don’t have to write mocks for anything you’re integrating with - just use hardhat to send TX from a different address. This is a HUGE time saver - to the point where I almost never had an isolated local node running. Quite proud of how frictionless the test suite was to run, to be honest.

Testnets are Not As Clean As You Think
Perhaps this problem was exacerbated by my timing, but deploying to testnet was a pain because:
- Some platforms had different contracts on testnet than they did on mainnet. So documentation was behind, sometimes the changes were not backwards-compatible, and I had to code in-faith that they’d have deployed to mainnet by the time we were ready to launch.
- The Ropsten, Rinkeby and Kovan nets were being deprecated, and everyone hadn’t moved over properly to Goerli yet.
- Getting Goerli ETH was such a pain. Faucets were clogged or drained, and I had to waste multiple hours of my time and several days of CPU cycles to get enough testnet ETH. Not cool.
The decentralized community is incentivised to perform various actions on the mainnet (LP, nodes). Who has an incentive to run testnet nodes? It has to be the centralized players behind the smart contracts. No one cares enough to deploy contracts to arbitrum-goerli, so they test on eth-goerli. But USDT-ETH is empty, and 1 ETH is a million DAI. Also, there are subtle differences between arbitrum-goerli and eth-goerli; So when you are building a contract that interfaces with many other contracts, you are necessarily doing a bit of testing in production.
Decentralized Price Feeds For Frontend
For all the hullaballoo about decentralizing frontends that I’ve been hearing forever, I was really surprised when I couldn’t find a decentralized price feed to show to the traders (think TradingView Charts on the frontend, marked by their positions and drawings). ALL the options were centralized, and were too expensive for a beta launch, and had terrible granularity (once per 5 mins? really?). I’m talking spot prices, not even OHLC or something fancier. We have Chainlink prices every block, why can’t we just make a subgraph on the graph? We have DEXs with subgraphs, why can’t they have prices? (sometimes one of a few of these things did exist, but NOT FOR L2s. UGH!). Why can I not easily deploy the code of a subgraph to a different chain? Why can’t I build on top of a subgraph’s output without re-indexing the entire chain?
Shout-out to my homies at Coingecko and DefiLlama for giving us free access to their APIs so we could at least keep building. I love animals! (NFA)
Why Are Audits So Expensive?
Of course, being our first novel smart contract system, we wanted to make sure it was audited by someone more experienced. We used our experience, lessons learnt from Ethernaut, integrating knowledge of hacks we saw, and tools like Slyther and Mythril to get “audit ready”. Yet, audits costs would be so prohibitively expensive (6 figures!) that we’d definitely not be able to do that without VC money or launching a token (neither of which we wanted to do at this point in time).
I’m not sure why 6 figure audits are a thing. Was that because of the bull market? It also looks like that auditor incentives are not aligned with the protocol’s - auditors don’t pay anything (except perhaps with reputation currency) in the case of a hack. Our strategy was to do a controlled launch (limited users, limited money that they could put in), until we had enough money to pay for an audit. We also planned on rolling out a small bug bounty right from the alpha release to incentivize people to find bugs.

If I was doing it now, I’d probably be using GPT3 a bit for security analysis. A team (Fortephy) has already done some work on using AI to do audits much cheaper. I’d probably talk to people from the Code4rena community to see if they could help us out as well.
Frontend
Typing: Coding once is for n00bs, you got to do it twice to really learn
You have written your contracts, and you have the abi. How do you use them in your frontend?
Oh but first, we have to write those tests in typescript right? How do we handle calls to the contract, without going back and forth to figure out the exact functions and calldata? hardhat-ethers makes this as easy as <contract>.connect(<wallet>).<fnname>(<data>) and you have nice autocomplete available if you type the contract properly thanks to typechain.
But when you come to the front end, you cant simply copy paste this code you so painstakingly wrote, because hardhart-ethers is not a front end thing, because…well, you aren’t using hardhat.
This is where it gets a bit painful on 2 counts:
-
If you are writing truly reactive code, using say
react-queryto read from an RPC, andwagmi’susePrepareContractWriteanduseContractWriteflows, you need to ditch all theawaitsfrom the tests. I think this is excellent practice, as it forces you to limit your async code and extract out the non-async code as functional components. We didn’t quite do that in our tests so some refactoring was in order. -
The bigger problem though was the typing. We couldn’t get the
typechaininterfaces to play well with wagmi, which only accepts ABIs. The best way to do this is to convert your json abi files (from theartifactsfolder) intotsfiles and then load the abi intousePrepareContractWrite. You then get static type-checking, but it is subtly different from thetypechaininterface (which has a lot of utility functions especially when it comes to things like enums). And so you resign to your fate of re-organizing the tests you already wrote to fit into the front end. But hey you learn to write disciplined functional code in the process. Win some, lose some, right? 7
Writing TXs != POST
Writing TX to a blockchain is all async, so it’s not like your usual HTTP POST call. When you send a tx, you have to wait for it to be mined, and then you want to wait for the block to be confirmed. This process could take a while and the UI needs to reflect that.
This gets particularly complicated when the first tx needs to be followed up with a second tx (create a fund, set rules for the fund after you create it). You need to make sure that the second tx is sent only after the first tx is confirmed. You could let the user operate on an expected state meanwhile, but you might end up having to revert the state if the first tx fails.
The graph also only returns data from confirmed txes, you would need to store these pending state in local storage, and merge them with the graph data if the page gets refreshed. If the user opens the app in a different browser, they wont see this unconfirmed data. The UI needs to make sure that the user is aware of this.
WAGMI helps you handle some of these state changes using React Hooks, but the UX around this takes some thought.

Take The Time To Search For Nice Libraries
We’ve already mentioned WAGMI above. This + RainbowKit encapsulate a lot of the complexity of interacting with the blockchain - chain selection, transaction broadcasting, reading from the chain - in a nice way.
TradingView was also super useful for everything we wanted to do out of the box.
If we hadn’t used these, we would have had to write a lot more code to handle all the edge cases.
Where Does Frontend Get Info?
Firstly, it’s important to use a decentralized service, but The Graph hadn’t decentralized yet (not on L2s at least). Infura hasn’t decentralized yet. Both have plans of doing so.
Secondly, you also have to decide what to use The Graph for, what to use the wallet’s provider for, and what to use Alchemy for when the dapp is not connected to the wallet. \
Also worth mentioning: Every time I mentioned The Graph some dev that we were using The Graph, they sounded concerned and asked us about the backup plans.
It’s also interesting that token lists are maintained as JSON files in frontend repos. Then you have to maintain one for each testnet. Some don’t have the tokens you want. Similarly, you have to curate a list of addresses that are related to your protocol, times each chain you’re deploying on.
Community
Community Makes or Breaks This Space of Builders
One of the biggest surprises in my short dev career is how helpful devs can be. Uniswap was one of my first protocol integrations and I was having quite some trouble different aspects (especially with LP-ing). I was able to get help from CryptoRachel on their discord. I was similarly having trouble with the GMX integration, and Itburnz was able to help me out. Itburnz has since become a friend of the project and joined our discord. I’ve mentioned Gelato, DefiLlama and coingecko before. I’ve also had the pleasure of taking help from various individuals who joined our twitter and startups that agreed to let us test their product for free. (Already mentioned Fortephy before, and there was also Guardrail)
On the flip side, I’ve stopped working on some integrations and products because nobody answered my questions.
What I’ve found is as long as you are nice and respectful, describe the problem in the right level of detail and tell them what you’ve tried, people are generally willing to help you with pointers and advice.
Mandatory reading that teaches you this: https://stackoverflow.com/help/how-to-ask
Having Usable, Latest Documentation is Important
This should be really self-explanatory for any open-source project, especially things people build on top of.
I won’t belabour this point, other than the fact that it inspired me to create https://barren-wuffet.gitbook.io/barren-wuffet/ and think about how to structure it for various audiences.
Keep Buidling, Degens!
Thanks for reading all the way down this laundry list of learnings, and for tolerating the occasional whiny vents .-.

-
If you’re curious why: a lot of smart contracts do
msg.senderbased accounting instead of position based ones. This means we need to deploy new child contracts to keep the positions of funds separate (for security reasons mostly). ↩ -
I believe the “Diamond Pattern” is in vogue now, but I didn’t get the chance to use that (would be overkill). ↩
-
Cosmos SDK does ↩
-
In fact, anyone, if you want the contract to be decentralized ↩
-
If the fund manager is whitelisted to run a bot to execute the trigger, that means they have to run special infrastructure to use the system which makes their lives harder. It also means, we can trust whatever the whitelisted bot does, so the bot can handle the IFTTT triggers and we don’t have to do this in-contract so the entire architecture will be different. ↩
-
Well… is anything really that easy in this space? Arbitrum had just done the Nitro upgrade, and hardhat’s forking broke. I hope they’ve patched it by now. ↩
-
Here I must thank CoPilot for easing my burden somewhat, this is exactly the kind of thing humans shouldn’t be doing. ↩



Leave a comment